









Delivering high performance computing through interconnected solutions
Charlie Foo, VP & General Manager, Asia Pacific/Japan, Mellanox

Charlie Foo, VP & General Manager, Asia Pacific/Japan, Mellanox
 With computing and storage devices accelerating and operating at a very fast speed, the bottleneck tends to rest on the network. This leads to the emergence of a need for innovation in both, speed and smarts. By providing low-latency, high-bandwidth, high message rate, transport offload to facilitate extremely low CPU overhead, Remote Direct Memory Access (RDMA), and advanced communications and computations offloads, Mellanox’s interconnected solutions are the most deployed high-speed solutions for large-scale simulations by delivering the highest scalability, efficiency, and performance for HPC systems today and in the future. Mellanox smart offloading such as RDMA and GPUDirect capabilities can dramatically improve neural network training performance and overall machine learning applications.
With demanding application requirements, HPC and AI clusters are getting larger. Some applications need millions of cores to run in parallel. The communications between computing cores, as well as computing and storage functionalities are becoming more critical for application performance.
With computing and storage devices accelerating and operating at a very fast speed, the bottleneck tends to rest on the network. This leads to the emergence of a need for innovation in both, speed and smarts. By providing low-latency, high-bandwidth, high message rate, transport offload to facilitate extremely low CPU overhead, Remote Direct Memory Access (RDMA), and advanced communications and computations offloads, Mellanox’s interconnected solutions are the most deployed high-speed solutions for large-scale simulations by delivering the highest scalability, efficiency, and performance for HPC systems today and in the future. Mellanox smart offloading such as RDMA and GPUDirect capabilities can dramatically improve neural network training performance and overall machine learning applications.
With demanding application requirements, HPC and AI clusters are getting larger. Some applications need millions of cores to run in parallel. The communications between computing cores, as well as computing and storage functionalities are becoming more critical for application performance.In-network computing, adaptive routing and self healing technology based smart network can improve application performance, avoid congestion and link failure issues in data center
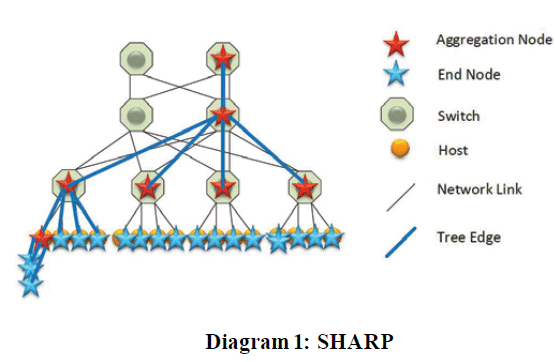
 In all distributed applications, the CPU does both application computing and communication computing. If the communication function occupies more CPU resources, the application will not have adequate CPU resources and vice versa. The best HPC and AI systems need to have the balance between the application and communication. Mellanox’s solution puts the communication computing in InfiniBand HCA (Host Channel Adapter) and switches, leaving all of the CPU resources to run the application. In-network computing technology performs data algorithms within the network devices, delivering ten times higher performance, and enabling the era of “data-centric” data centers. Using in-network computing technologies not only gives application more CPU resource, but also reduces CPU jitters on the application. Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) is the technology that delivers this. Please refer to Diagram 1, all of communication computing operations such as data synchronization, data movement, and collective operation between all end nodes (hosts) can be done in the aggregation nodes (switches), no need go to CPU. A good use case for SHARP is the Allreduce operation in machine learning. The switch can be used to implement the Allreduce and avoid the many to one communication between workers to parameter.
In all distributed applications, the CPU does both application computing and communication computing. If the communication function occupies more CPU resources, the application will not have adequate CPU resources and vice versa. The best HPC and AI systems need to have the balance between the application and communication. Mellanox’s solution puts the communication computing in InfiniBand HCA (Host Channel Adapter) and switches, leaving all of the CPU resources to run the application. In-network computing technology performs data algorithms within the network devices, delivering ten times higher performance, and enabling the era of “data-centric” data centers. Using in-network computing technologies not only gives application more CPU resource, but also reduces CPU jitters on the application. Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) is the technology that delivers this. Please refer to Diagram 1, all of communication computing operations such as data synchronization, data movement, and collective operation between all end nodes (hosts) can be done in the aggregation nodes (switches), no need go to CPU. A good use case for SHARP is the Allreduce operation in machine learning. The switch can be used to implement the Allreduce and avoid the many to one communication between workers to parameter.
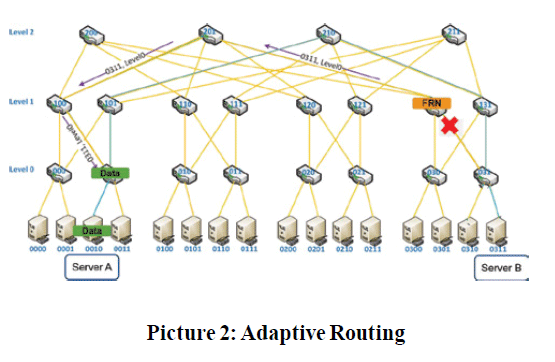
 In HPC and AI systems, the communication between computing node and storage should be the reliable communication. This means they should not have the packet drop during the communication between any nodes. However, there is a propensity of network congestions caused by the communication models of HPC and AI, such as the Allreduce communication. These congestions will lead to the packet drop. Smart solutions like AR (Adaptive Routing) and SHIELD (Self Healing Communication Technology) from Mellanox not only resolve congestion issues, but also help the network avoid the congestion and packet drop. AR uses the specific packet (adaptive routing notification) to detect the congestion of next few hops before the switch sends the actual data packet to next hop. If that packet indicates that the congestion may happen in following hops, then switch can automatically change the routing path to new path to avoid the congestion happening in the original path. Please refer to picture 2.
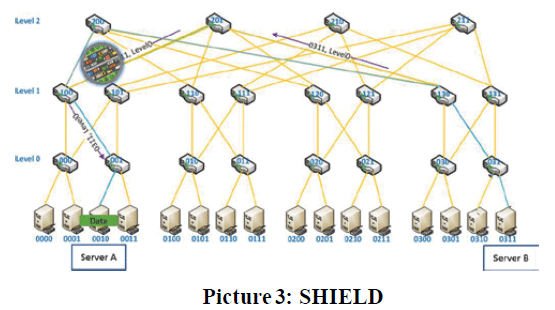
SHIELD resolves the link failure issue between the sender and receiver at switch level without the application being aware. If there is a link failure, such as cable, transceiver or switch port issues, the closest switch can identify the failure and send the special packet (fault recovery notification) back to uplink switches until the right switch is identified and the packet is re-routed to a healthy link. If we rely on application to identify the link failure, it takes about 5 to 30 seconds in 1K to 10K node clusters. SHIELD can detect and fix the link failure within a few milliseconds without application involvement. Please refer to picture 3.
In summary, acceleration of the computing, storage and smart network (adaptive routing, fabric automation and recovery) has become imperative in this age of HPC, AI and Digitalization, when there is no room for performance compromise. Mellanox's scalable HPC and AI interconnect solutions are paving the road to Exascale computing by delivering the highest scalability, efficiency, and performance for HPC and AI systems today and in the future.
In HPC and AI systems, the communication between computing node and storage should be the reliable communication. This means they should not have the packet drop during the communication between any nodes. However, there is a propensity of network congestions caused by the communication models of HPC and AI, such as the Allreduce communication. These congestions will lead to the packet drop. Smart solutions like AR (Adaptive Routing) and SHIELD (Self Healing Communication Technology) from Mellanox not only resolve congestion issues, but also help the network avoid the congestion and packet drop. AR uses the specific packet (adaptive routing notification) to detect the congestion of next few hops before the switch sends the actual data packet to next hop. If that packet indicates that the congestion may happen in following hops, then switch can automatically change the routing path to new path to avoid the congestion happening in the original path. Please refer to picture 2.
SHIELD resolves the link failure issue between the sender and receiver at switch level without the application being aware. If there is a link failure, such as cable, transceiver or switch port issues, the closest switch can identify the failure and send the special packet (fault recovery notification) back to uplink switches until the right switch is identified and the packet is re-routed to a healthy link. If we rely on application to identify the link failure, it takes about 5 to 30 seconds in 1K to 10K node clusters. SHIELD can detect and fix the link failure within a few milliseconds without application involvement. Please refer to picture 3.
In summary, acceleration of the computing, storage and smart network (adaptive routing, fabric automation and recovery) has become imperative in this age of HPC, AI and Digitalization, when there is no room for performance compromise. Mellanox's scalable HPC and AI interconnect solutions are paving the road to Exascale computing by delivering the highest scalability, efficiency, and performance for HPC and AI systems today and in the future. 
